AI Development Framework 2.0: From Chaos to a Self-Improving System
How we evolved our AI development framework with automated guardrails, context compaction, and self-improving memory, so we can ship fast without accumulating technical debt.
A few weeks ago, I wrote about building a structured AI development framework that treated AI like a development team, not a chatbot. It worked. MetaScope shipped.
But shipping isn’t the hard part. Sustaining quality under speed is. After a stretch of intensive development, we started seeing a familiar set of failure modes: files ballooning, long sessions getting muddy, and the same corrections resurfacing after a few days.
Framework 2.0 is what we built to stop that drift. It’s a system that prevents debt, stays sharp under long tool chains, and remembers corrections so they don’t keep costing you time.
The problem with Framework 1.0
Framework 1.0 solved the obvious problems: context loss, inconsistent quality, documentation drift. It introduced specialized agents, quality gates, and persistent memory.
Then the scale problems showed up.
Debt still accumulated
Even with reviews and gates, files kept growing. One SwiftUI view hit 6,635 lines. A service ballooned past 80 methods. The framework could detect problems, but it didn’t reliably prevent them.
Context saturation
Long sessions degraded. After enough tool calls, outputs started to loop: circular reasoning, vague suggestions, and repeated exploration. The model wasn’t “worse” - it was overloaded.
Learning didn’t persist
Corrections were local. “No, use CustomButton not HTML button” could be fixed in the moment, then resurface a week later. The knowledge lived in my head, not in the system.
Agent proliferation
Ten agents became noisy. Overlapping responsibilities led to uncertainty about who should do what, and when. The process began to cost attention.
Framework 1.0 helped build the product. Framework 2.0 is about keeping it maintainable while the pace stays high.
The solution: three core innovations
Framework 2.0 rests on three pillars:
- Guardrails: enforcement that blocks debt before it enters the codebase
- Context engineering: deliberate compaction to keep sessions in a “smart zone”
- Self-improving memory: a workflow that turns corrections into durable rules
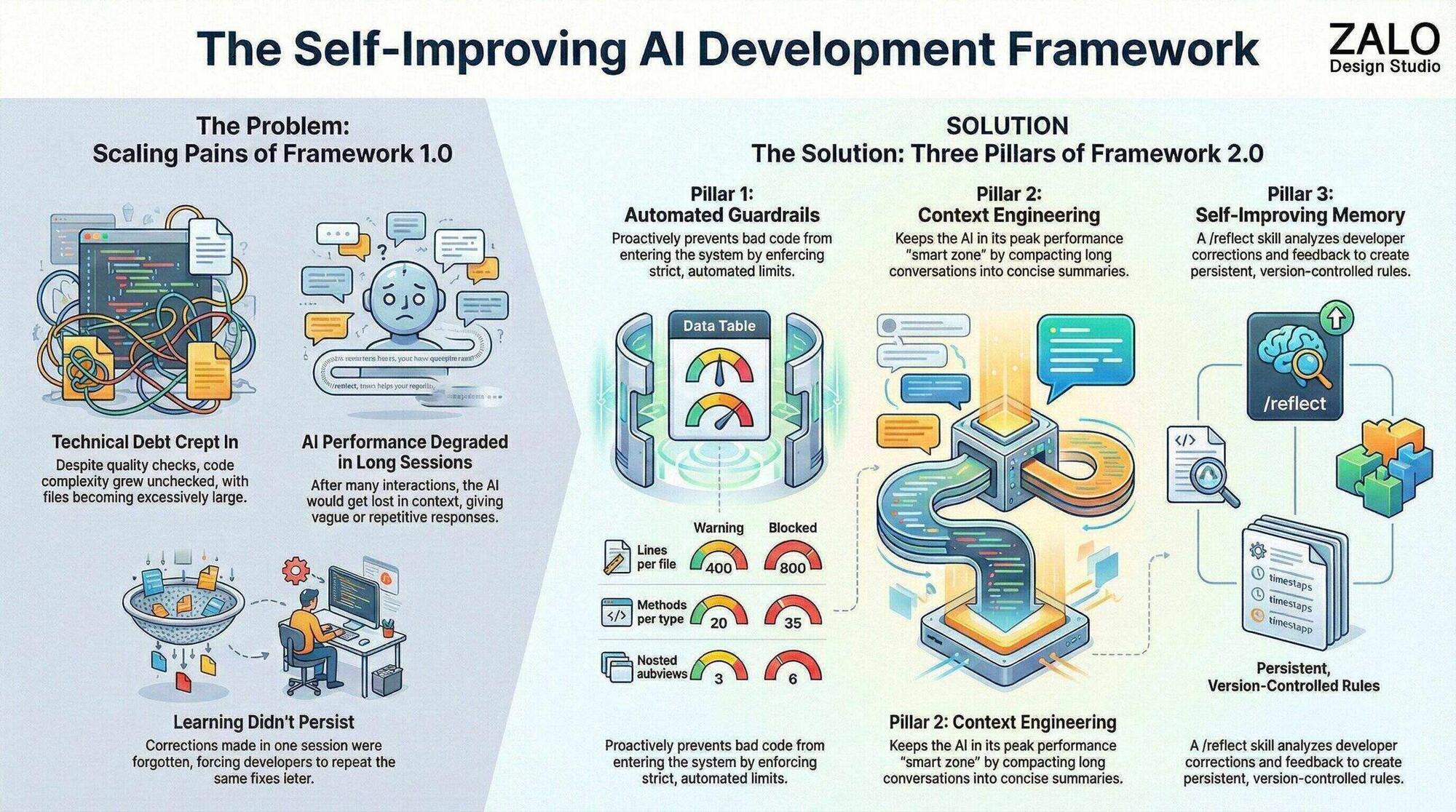
Pillar 1: Guardrails
Quality gates catch problems after they exist. Guardrails stop problems from getting merged in the first place.
The limits
Every metric has two thresholds:
| Metric | Soft cap | Hard cap | Enforcement |
|---|---|---|---|
| Lines per file | 400 | 800 | Reviewer warns / Validator blocks |
| Lines per SwiftUI view | 300 | 600 | Reviewer warns / Validator blocks |
| Types per file | 5 | 12 | Reviewer warns / Validator blocks |
| Nested subviews | 3 | 6 | Reviewer warns / Validator blocks |
@State per view | 10 | 20 | Reviewer warns / Validator blocks |
| Methods per type | 20 | 35 | Reviewer warns / Validator blocks |
Soft caps trigger warnings. The reviewer flags them as medium severity during PR review.
Hard caps are blocking. The validator refuses to proceed (ideally in CI and/or pre-commit), unless there’s an explicitly tracked exception.
The net reduction rule
If you touch a file that’s already over soft cap, your PR must reduce its size by 5–10%.
That shifts the default behavior from “debt pauses” to “debt shrinks.” Every small fix becomes a small cleanup.
Exception tracking
Sometimes limits must be exceeded. Framework 2.0 handles this with structured, expiring exceptions:
// metascope:exception(metric:lines, value:1200, reason:"Complex multi-tab view pending refactor", issue:234, expires:"2026-02-28")
struct SettingsView: View {
// ...
}Exceptions require:
- an issue reference (
issue:234) - an ISO date (
YYYY-MM-DD) - a concrete reason (no “temporary” without a plan)
The auditor tracks expired exceptions and reports them. No exception lives forever.
Skills for remediation
When guardrails trigger, the framework provides playbooks:
swiftui-decomposition: systematic view extraction with scoring criteriagod-object-splitter: service decomposition patterns (facade, strategy, factory)static-data-externalizer: moving content out of Swift into resources
These aren’t guidelines. They’re procedures: extraction criteria, proposed file trees, and migration steps.
Pillar 2: Context engineering
Long sessions don’t fail loudly. They fail quietly: the conversation gets heavier, the model becomes more repetitive, and progress slows.
Framework 2.0 treats that as a systems problem.
The “smart zone”
In practice, shorter, cleaner context produces sharper output, especially during debugging and architectural decisions. When sessions get long, dead ends and speculative threads pollute the working set.
Framework 2.0 adds a compaction-protocol skill that triggers when:
- debug sessions exceed 10 tool calls without resolution
- agent attempts fail repeatedly
- exploratory research completes
- you’re about to start a complex implementation phase
- the conversation starts to feel circular or “muddy”
What compaction produces
Instead of dragging the whole transcript forward, compaction produces a truth-grounded artifact:
## Context compaction: Photos XPC connection recovery
**Session focus**: Fix Photos library becoming unresponsive after sleep
**Compaction reason**: Debug session >15 tool calls
### Ground truth
| File | Line | Factual finding |
| --- | ---: | --- |
| `PhotosConnectionManager.swift` | 145 | Callback does **not** fire when daemon dies during sleep |
| `ThumbnailImageLoader.swift` | 312 | Error check missing `com.apple.accounts` pattern |
### What doesn’t work
- ❌ Single-request probes: pass even when bulk requests fail
- ❌ Waiting for callback: `photoLibraryDidBecomeUnavailable` unreliable
### Recommended next step
Implement bulk probe (5+ concurrent requests) in `handleAppDidBecomeActive()`.Every claim points to file:line. Failed approaches are recorded with the reason they failed. The next session starts with signal, not noise.
Compaction quality checklist
- Every claim references
file:line(no speculation) - Failed approaches documented with specific reasons
- Files listed are actually relevant
- Next step is single and actionable
- Constraints are grounded in code, not assumptions
Pillar 3: Self-improving memory
The most expensive mistake isn’t a bug. It’s paying for the same correction repeatedly.
Framework 2.0 formalizes learning through a /reflect skill.
The /reflect skill
At the end of significant sessions, invoking /reflect triggers an analysis:
## Signals detected
### Corrections (high confidence)
1. "No, use CustomButton not HTML button"
- Category: Components
- Proposed rule: "Always use CustomButton for buttons in MetaScope"
2. "Check for SQL injections"
- Category: Security
- Proposed rule: "Validate all user input for SQL injection"
### Approvals (medium confidence)
1. Code using @StateObject was accepted
- Category: SwiftUI patterns
- Proposed rule: "Prefer @StateObject for view-owned state"The system scans for explicit corrections (“No, use X instead”), approvals (“That’s exactly right”), and repeated patterns in accepted code.
Confidence levels
| Level | Source | Example |
|---|---|---|
| High | Explicit rules, negatives | “Never do X”, “Always use Y” |
| Medium | Patterns that worked | Code that was accepted/merged |
| Low | Observations | Inferred preferences to review |
High-confidence learnings become rules. Medium-confidence become patterns. Low-confidence become observations that get reviewed and pruned.
Persistent, version-controlled memory
Learned preferences live in .claude/memory/learned-preferences.md:
# Learned preferences
## Rules (high confidence)
### Components
- Always use CustomButton for buttons in MetaScope (2026-01-08)
- Never create inline styles for buttons (2026-01-05)
### SwiftUI patterns
- Prefer @StateObject for view-owned state (2026-01-08)
- Use .task instead of .onAppear for async work (2026-01-07)
## Change log
| Date | Changes | Confidence |
| --- | --- | --- |
| 2026-01-08 | +3 rules | 2 high, 1 medium |This file is git-tracked. If a learning is wrong, you can revert it. The system improves without turning into an irreversible mess.
The feedback loop
Correction in session → /reflect detects → proposes update → user confirms → memory persists → future sessions apply rule → fewer correctionsThe consolidated agent system
Framework 2.0 reduces ten agents to seven, with cleaner boundaries:
| Agent | Role | Model | Trigger |
|---|---|---|---|
| architect | Design docs, implementation plans | Opus | Before medium+ features |
| validator | Automated quality checks | Sonnet | Before any commit |
| docs-sync | Documentation updates | Sonnet | After feature/fix completion |
| committer | Git operations | Sonnet | After validator passes |
| reviewer | Human-style code review | Opus | Before merge |
| debugger | Build/runtime/test failures | Opus | After 1+ failed debug attempts |
| auditor | Pattern consistency audits | Sonnet | Before major refactors |
What changed
Several agents merged into docs-sync with three modes:
- SYNC: update docs after feature completion
- AUDIT: clean stale docs, validate folder hygiene
- COPYWRITER: generate blog posts and marketing copy
The goal wasn’t fewer agents for its own sake. It was less ambiguity.
The workflow
validator → docs-sync → committer → [user approval] → reviewer → mergeEach agent has one job. Each triggers at a predictable moment. The system stays quiet unless it has a reason to speak.
Skills: reusable procedures
Framework 2.0 formalizes skills, versioned SOPs you invoke when needed:
| Skill | Purpose |
|---|---|
git-workflow | Commit format, branch naming, safety rules |
code-review-checklist | What to check, severity classification |
documentation-sync-map | Doc locations, sync rules, hygiene |
swift-patterns | MetaScope conventions and anti-patterns |
compaction-protocol | Context compression to stay sharp |
reflect | Self-improving memory system |
codebase-guardrails | Limit enforcement before changes |
swiftui-decomposition | View extraction playbook |
god-object-splitter | Service decomposition patterns |
static-data-externalizer | Moving content to resources |
memory-audit | Periodic memory cleanup |
copywriter | Blog and marketing content templates |
metascope-guide | Codebase navigation and patterns |
Skills don’t bloat every conversation. They’re called on demand, so context stays lean while procedures stay deep.
The MCP server ecosystem
Framework 2.0 uses focused MCP servers for specialized capabilities.
Swift documentation server
Apple’s APIs change constantly, and training data has a cutoff. A Swift MCP server can provide current references:
mcp__swift__swift_symbol_lookup("NSWindow")
mcp__swift__apple_docs_search(query: "window management")
mcp__swift__swift_evolution_lookup("async")
mcp__swift__hig_search("navigation")Memory server
The MCP memory server provides a knowledge graph across sessions:
mcp__memory__search_nodes("v1.2.2 current work")
mcp__memory__add_observations({
entityName: "photos-xpc-pattern",
contents: ["Bulk probes required for reliable detection"]
})Results: what Framework 2.0 delivers
After 4 days with the evolved framework, here are the early signals.
Quantifiable outcomes (internal snapshot)
| Metric | Framework 1.0 | Framework 2.0 |
|---|---|---|
| Files over hard cap | 15+ | 0 (with tracked exceptions) |
| Average file size | ~560 lines | <400 lines |
| Session context saturation | Frequent | Rare |
| Repeated corrections | Common | Declining |
| Documentation drift | Occasional | None observed |
How these were measured (briefly):
- “Files over hard cap”: validator guardrail scan across the repo at the end of each day
- “Average file size”: line counts across Swift files in the main module (repo snapshot)
- “Repeated corrections”: manual tally from
/reflectoutputs + PR review notes - “Documentation drift”: docs-sync audit pass after merges
Qualitative outcomes
- Sustainable velocity: the codebase stops getting worse as you ship.
- Reduced cognitive load: the system carries the corrections and constraints.
- Predictable quality: standards aren’t dependent on mood.
- Institutional memory: decisions become durable artifacts.
How to adopt Framework 2.0
Start where Framework 1.0 left off
If you already have:
CLAUDE.mdwith quality gates- basic agent structure
- persistent memory
Add these progressively:
- Guardrails first: define soft/hard caps and enforce them
- Compaction protocol: produce truth-grounded artifacts for long sessions
- Reflect: run
/reflectafter meaningful work - Consolidate agents: remove overlap, clarify triggers
If starting fresh
- Create
CLAUDE.mdwith mandatory gates and guardrails - Define three core agents: validator, committer, reviewer
- Add MCP memory (and docs, if you can)
- Add guardrails after your first 1,000 lines
- Add compaction after your first long debug spiral
- Add
/reflectafter the first correction you never want to repeat
The key insight
Framework 2.0 isn’t “more process.” It’s process that maintains itself.
Guardrails prevent debt without manual tracking. Compaction protects session quality without discipline games. Reflection turns corrections into reusable rules.
Conclusion
Framework 2.0 is our response to entropy.
Without guardrails, complexity creeps in. Without compaction, context degrades. Without reflection, lessons evaporate.
If you adopt only one idea, make it this: guardrails with exceptions that expire. It’s the smallest change that reliably bends a codebase back toward health, and it sets you up for compaction and memory once the project gets real.