When developers first hear that Armature uses four distinct AI agents to generate a development environment, the natural question is: why? Couldn’t a single, well-prompted model just take a project description and produce the output files?
The short answer is yes, and the output would be mediocre almost every time.
This post explains the engineering rationale behind Armature’s four-stage pipeline, what each stage actually does, and why collapsing those stages into fewer would compromise the quality of what gets generated.
The problem with single-shot generation
Imagine asking a capable developer to write a complete CLAUDE.md, agent definitions, skill files, git hooks, CI/CD configuration, and contributing guidelines for a project they know nothing about. All in one continuous output, no questions asked.
They would make assumptions. Those assumptions would be inconsistent. The git hooks might enforce a workflow that conflicts with the CI pipeline. The agent definitions might include tools the project has no use for. The CLAUDE.md might describe an architecture that was never confirmed with anyone.
The developer would have been better served by a structured conversation first: what is the project, what is the tech stack, what workflows matter, what are the team’s constraints? Then a design phase to think through the architecture. Then a planning phase to break that architecture into a sequence of deliverable work. Then the assembly that produces the actual files.
That is precisely the shape of Armature’s pipeline.
The four stages at a glance
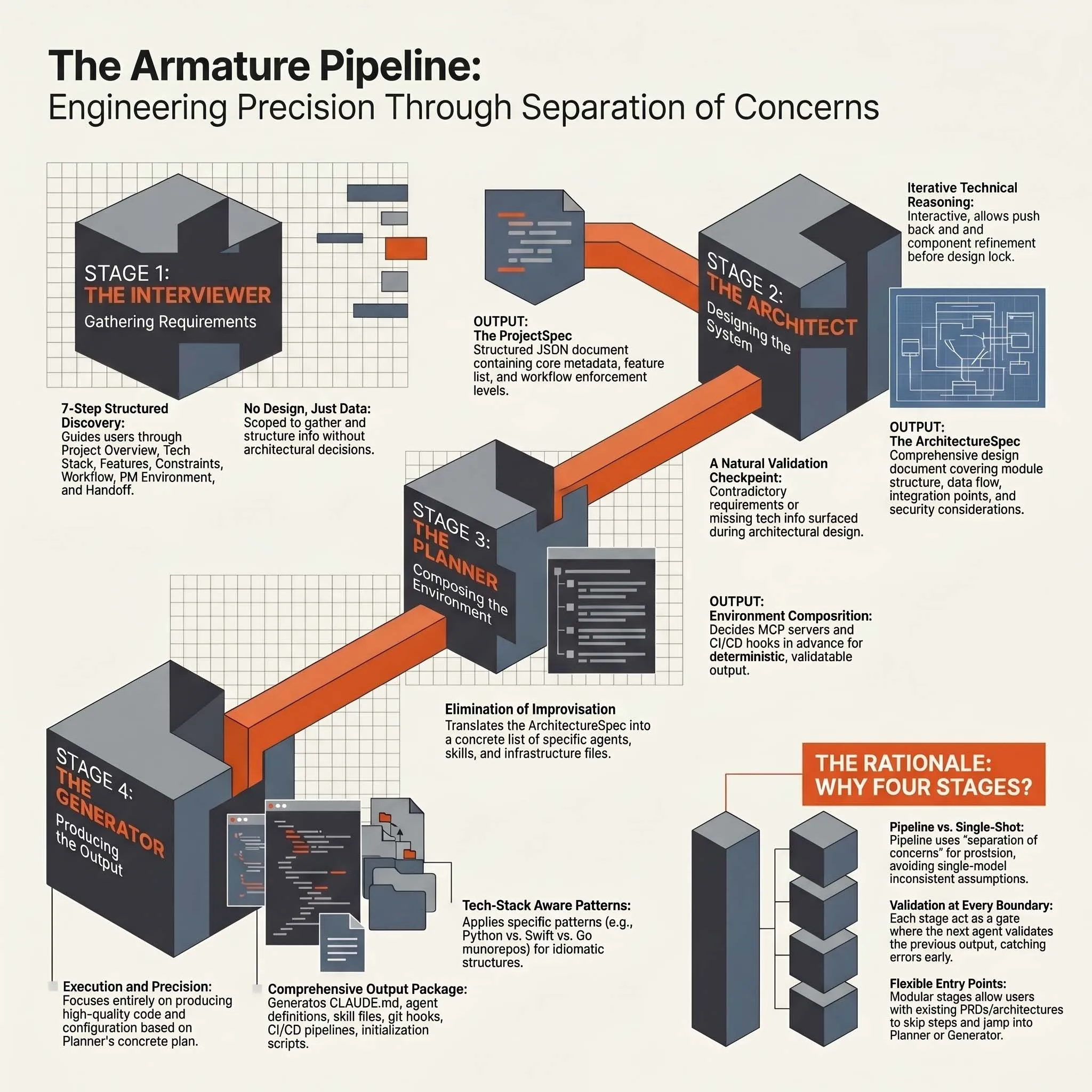
Each stage has its own AI agent, its own system prompt, its own defined input and output, and its own role in the handoff chain. The output of each stage becomes the validated input to the next.
Stage 1: Interviewer
The Interviewer is a conversational agent. Its job is not to make decisions, it is to surface the information needed to make good decisions later.
It guides the user through seven progressive steps:
- Project overview, what the project is and what problem it solves
- Tech stack, languages, frameworks, databases, deployment targets
- Features, the core capabilities the project needs
- Requirements and constraints, compliance needs, team size, code quality standards
- Autonomy and workflow, branching strategies, PR practices, review processes
- PM and environment, issue tracking, project management tooling, release cadence
- Confirmation and handoff, structured review of everything gathered before proceeding
As the conversation progresses, the Interviewer uses tool calling to extract structured data from the user’s responses. By the end of step seven, it has produced a ProjectSpec: a structured JSON document containing the project name, project type, tech stack, feature list, autonomy mode, and workflow enforcement level.
The key design decision here is that the Interviewer does not attempt to design anything. It is explicitly scoped to gathering and structuring information. This is not a limitation, it is a constraint that makes the subsequent stages more reliable.
Because the Interviewer is model-selectable (Opus or Sonnet), teams can choose between a faster default and a more powerful model for complex or high-stakes interviews without sacrificing downstream quality.
Stage 2: Architect
The Architect takes the ProjectSpec and designs a complete system architecture. This stage defaults to Claude Sonnet, though it can be configured to use Opus for projects where deeper architectural reasoning is warranted.
Unlike the Interviewer, the Architect is interactive and iterative. The user can push back, refine, and explore alternatives before locking in the design. The Architect proposes:
- System components and their responsibilities
- Module structure and file organization
- Data flow between components
- Integration points with external services
- Security architecture
- Scalability considerations
The output is an ArchitectureSpec, a detailed design document that goes well beyond what a simple tech stack declaration could capture.
This separation from the Interviewer stage matters for a subtle reason: the questions worth asking an architect are different from the questions worth asking a product owner. The Interviewer is optimized for surfacing requirements in plain language. The Architect is optimized for translating those requirements into technical decisions. Conflating the two would either push technical depth into the requirements phase (inappropriate) or leave architecture decisions to a model that was told to stay conversational (also problematic).
The Architect also represents a natural checkpoint. If the ProjectSpec produced by the Interviewer contains ambiguities (contradictory requirements, an underspecified tech stack, missing information), those ambiguities surface during architectural design rather than silently propagating into generated files.
Stage 3: Planner
The Planner is the newest addition to the pipeline, and it addresses a gap that most Claude Code adoption stories quietly ignore.
The ArchitectureSpec describes what a system looks like. It says nothing about how the team should actually build it. Translating an architecture into a sequence of deliverable work (epics, stories with acceptance criteria, tasks, story points, and milestones) is its own reasoning step, and it is the step that most often gets skipped or hand-rolled in a way that drifts from the architectural intent.
The Planner takes the ProjectSpec and the ArchitectureSpec and produces a complete project plan:
- Epics, the major delivery units, derived from the implementation phases in the architecture
- Stories, individual deliverable units of work, each with acceptance criteria
- Tasks, the concrete steps that make up each story
- Story points and milestones, scoped against the project’s stated team size and cadence
The output is both a machine-readable project-plan.json (suitable for import into GitHub Issues, Jira, or Linear) and a human-readable docs/roadmap.md that ships inside the generated environment alongside the architecture.
This separation matters. An architecture without a work plan is a diagram. A work plan without an architecture is a wishlist. The Planner connects the two by translating architectural decisions into the actual sequence of stories that will deliver the system, with the same level of structural rigour the Architect applied to the system itself.
Because the Planner runs on a structured ArchitectureSpec rather than a raw conversation, the resulting plan stays consistent with the architecture it is meant to deliver. Teams that import the plan into their issue tracker get a backlog already aligned with the codebase Armature is about to generate.
Stage 4: Generator
The Generator receives the ProjectSpec and the ArchitectureSpec and assembles the complete development environment. It runs a DeterministicAssembler: a single-pass engine that selects the appropriate stack templates from the knowledge base, fills in template variables, and produces the full file tree. No LLM interaction is required for the core assembly. The output is deterministic given the same inputs.
What the Generator produces includes:
CLAUDE.md, the primary development guide for the generated environment- Agent definitions, specialized AI agents for the project’s workflows
- Skill files, reusable capability modules (database skills, deployment skills, and so on)
- MCP server configuration
- Git hooks, pre-commit, commit-msg, and pre-push hooks calibrated to the project’s workflow enforcement level
- CI/CD pipeline configuration
- Documentation scaffolding (including
docs/roadmap.mdfrom the Planner stage when run) - Tools configuration and
settings.json - An initialization script to set up the environment
- Contributing guidelines and PR/issue templates
The Generator is tech-stack-aware. Python patterns differ from Swift patterns. A monorepo with a Go backend and a React frontend requires different file structures and different agent definitions than a Rails monolith. The stack templates encode these differences, and the Generator selects and composes them based on what the Architect specified.
Determinism is the key property. Because the Generator does not improvise (it executes a defined assembly against well-formed inputs), the same ProjectSpec and ArchitectureSpec will always produce the same generated environment. That makes the output reviewable, diffable, and reproducible, which matters when teams version-control the generated .claude/ directory alongside their source code.
The Generator is exposed through a multi-step configuration wizard in the UI, allowing users to review and adjust the assembly before files are written.
Why four stages instead of fewer
The instinct to simplify (to reduce four stages to two or three) is understandable. Each stage boundary adds coordination overhead. But the boundaries exist because the tasks are genuinely different in kind.
Gathering requirements requires conversation skills: asking clarifying questions, normalizing ambiguous answers, confirming before proceeding. A model optimized for this task should not simultaneously be reasoning about architecture.
Designing architecture requires deep technical reasoning about trade-offs. It benefits from iteration and user feedback. It should operate on a clean, structured ProjectSpec, not a raw transcript.
Planning the work requires translating an architecture into a sequence of stories and tasks with acceptance criteria. This is genuinely different from designing the architecture itself. An architect thinks in modules and integration points; a planner thinks in deliverable increments. Conflating them produces either over-engineered architectures with no clear path to delivery, or thin work plans that drift from the system they are supposed to build.
Generating files requires precision, determinism, and tech-stack knowledge. It should operate on validated structured inputs, not on a raw conversation. When the upstream stages have produced clean artefacts, the Generator can focus on correctness and completeness rather than making compositional decisions under uncertainty.
Each boundary is also an entry point. Users who already have a ProjectSpec from an existing PRD can skip the Interviewer. Users who have a defined architecture can skip ahead to the Planner. This flexibility comes for free when the stages are cleanly separated.
Validation at every boundary
One of the underappreciated benefits of the pipeline structure is that each stage validates the previous stage’s output before proceeding.
The Architect surfaces ambiguities in the ProjectSpec. The Planner catches architectural decisions that cannot be translated into a coherent sequence of deliverable stories (over-scoped phases, missing dependencies, ambiguous module boundaries). The Generator can flag stack-template mismatches or missing fields that would otherwise produce broken output.
In a single-shot system, these validation opportunities do not exist. Errors in requirements silently propagate into generated files. Inconsistent architectural decisions become inconsistent configuration. There is no intermediate state to inspect or correct.
The four-stage pipeline makes errors visible at the stage closest to their origin, where they are cheapest to fix.
Conclusion
Armature’s four-stage pipeline is not complexity for its own sake. It reflects a recognition that requirements gathering, architectural design, work planning, and environment assembly are distinct cognitive tasks, and that conflating them produces worse output than separating them.
Each stage is scoped to what it does well. Each boundary is a validation checkpoint. Each output is a structured artifact that the next stage can reason about reliably.
The result is a generated development environment that reflects the actual requirements of a project rather than a best-guess interpolation from a single overloaded prompt.
For the bigger picture on what Armature produces, see Introducing Armature. Armature is delivered today inside Zalo Design Studio’s AI Product Acceleration engagements; get in touch and we will generate your environment as part of yours.
Armature is a meta-framework for generating customized Claude Code development environments. The generated output is designed to be read, understood, and modified by the teams that use it.