Every software studio uses AI now.
Usually that means a developer opens a chat, pastes in some code, gets a suggestion, and decides whether to accept it. Helpful, but still fundamentally human-led execution with AI support around the edges.
That is not how we are working.
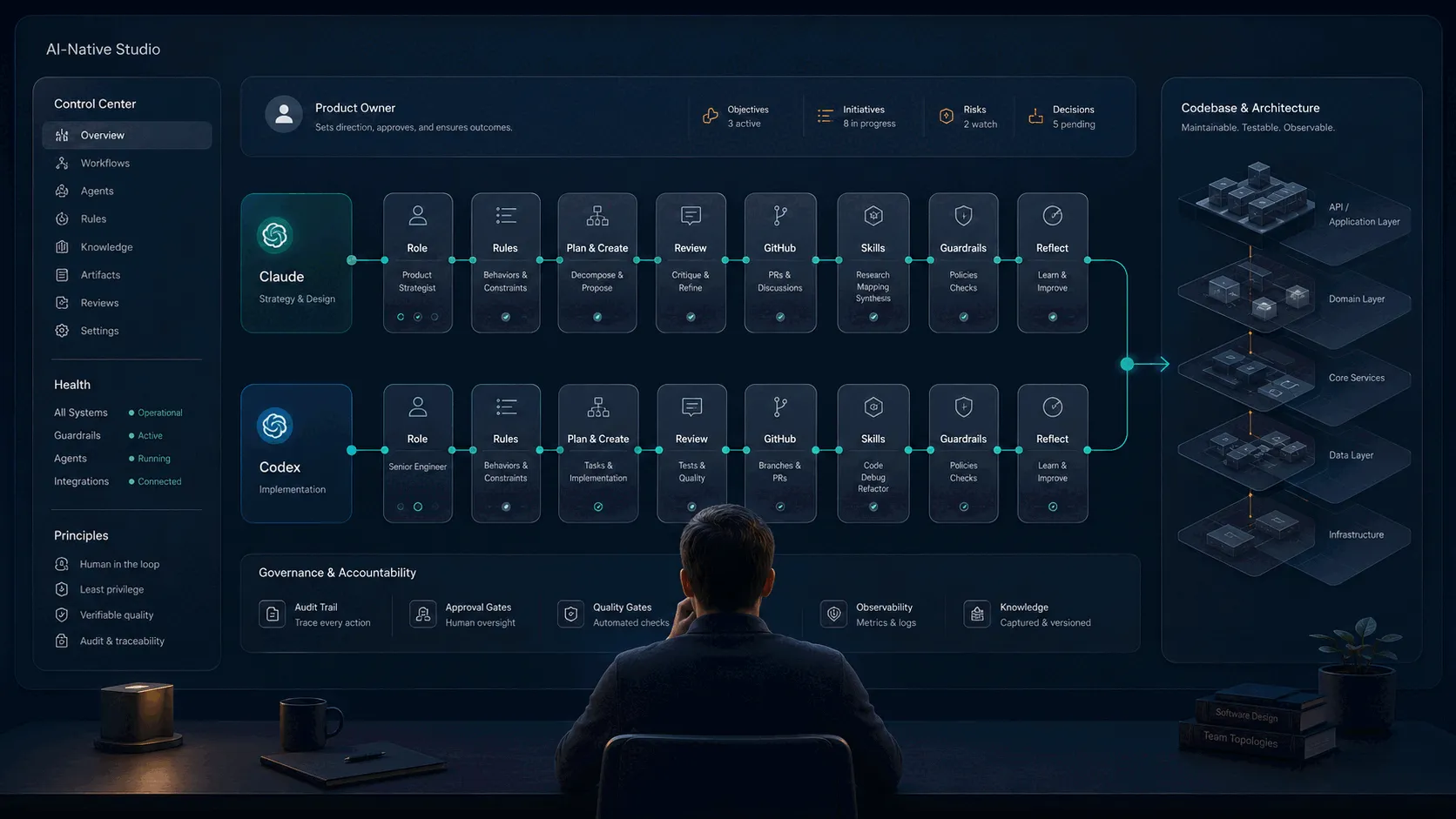
Over the past few months, Zalo Design Studio has been building MetaScope, a professional macOS metadata editor, with a deliberately small team: one human product owner and two AI agents, Claude and OpenAI Codex, working on a real codebase together.
Not as autocomplete. Not as isolated assistants. As collaborators with roles, rules, review cycles, and a chain of accountability.
The main lesson has been surprisingly practical:
The hard part is not access to powerful models. The hard part is building the system around them.
How does an agent know enough about the codebase before touching it? How does it avoid confidently changing the wrong thing? How do two agents divide work without colliding? How does the team remember past mistakes and become better over time?
Those questions forced us to build what is effectively an operating system for AI agents.
This is how it works.
The shape of the team
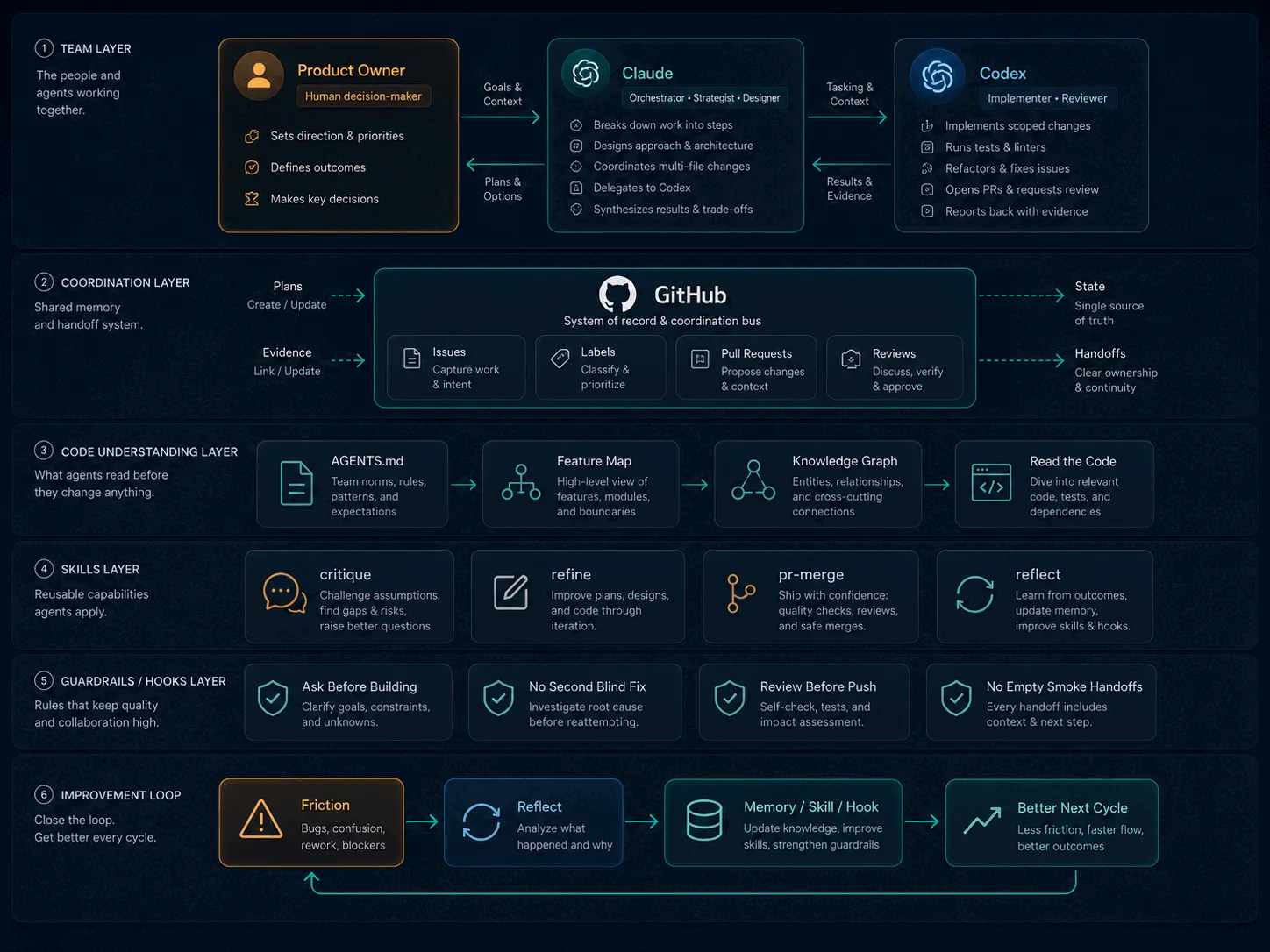
The team has three roles, and the separation matters.
I am the product owner.
I decide what matters, what ships, what feels right in the actual product, and whether the work is good enough for users. I review outcomes, test the application, make product trade-offs, and set direction.
What I do not do is review every diff line by line.
That might sound reckless. In practice, it makes the system better. It means quality cannot depend on me acting as a hidden safety net for every implementation detail. The workflow has to be accountable on its own.
Claude runs interactively in my terminal.
It handles orchestration, multi-file changes, documentation, implementation planning, and the more complex design conversations.
Codex runs separately in another clone of the repository.
It wakes on a timer, picks up focused work, implements contained changes, and, critically, reviews Claude’s pull requests.
The two agents do not talk directly.
They coordinate through GitHub.
Issues, labels, pull requests, and structured comments are the shared memory of the system. A pull request is a deliverable. A label change is a handoff. A review comment is a decision point. The state lives somewhere inspectable, durable, and accountable.
There is no side-channel chat between the agents because chat is too easy to lose, misremember, or reinterpret. GitHub gives the work a shared ledger.
The real structure is not “a human and two AIs.”
It is one product owner, one implementer, and one reviewer, where the implementer and reviewer happen to be AI agents. The human decision-maker is still load-bearing. The interesting part is that the implementation and review loop can now run with a level of continuity and discipline that would have been unrealistic for a small studio before.
A constitution both agents read
The system starts with one document: AGENTS.md.
It is the operating manual both agents read before acting. It defines how work moves, where truth lives, what must be verified, and which failure modes the agents are expected to avoid.
A few rules capture the philosophy.
GitHub is the coordination bus.
State lives in issues, pull requests, labels, and comments. Not in an agent’s memory. Not in a side conversation. When a document and GitHub disagree, GitHub wins.
One issue, one pull request, one squash merge.
Even small changes pass through the same workflow. That consistency matters because exceptions are where systems start to drift.
Verify before naming.
Before an agent refers to a menu, file path, feature, behavior, or scope, it has to inspect the source of truth. It cannot rely on what the name suggests. Confident-but-wrong is one of the most expensive AI failure modes, so the system is designed to reduce it directly.
Hypothesis first on second attempts.
If the first fix does not work, the agent has to stop editing and gather evidence. Add instrumentation. Reproduce the issue. Form a root-cause theory. Then make the next change.
A second blind guess is how a small bug becomes a long debugging spiral.
The important point is that AGENTS.md is not just a style guide. The most important rules are also enforced by the workflow around it.
Knowing the codebase before changing it
The easiest way for an AI agent to make a bad change in a mature codebase is to act on a partial picture.
It searches for a symbol, finds one file, sees something plausible, and starts editing. But real product logic is rarely contained in one obvious place. It is spread across data models, rendering paths, state coordination, feature flags, UI assumptions, tests, and old decisions that only make sense in context.
So the default workflow is not search and edit.
It is map, graph, read.
First, the agent consults a feature-surfaces map. This is a hand-curated reverse index of the product. For each user-facing feature, it lists the surfaces involved: data layer, rendering layer, coordination logic, design notes, and related implementation details.
Then it uses a generated codebase knowledge graph to confirm the surrounding structure. The graph clusters the code into communities, which helps the agent see whether the file it found is central, peripheral, or only one part of a larger pattern.
Only after that does it read the affected files properly. Not just the one file it wants to edit, but the caller above it and the things it calls below.
That discipline sounds small. It is not.
It is often the difference between fixing the real bug and fixing a nearby stub that looked important because it matched the search term.
Skills instead of improvisation
Anything the studio does more than twice becomes a skill.
A skill is a written procedure the agent invokes by name. The goal is simple: important work should not depend on the agent improvising the right checklist from memory each time.
Some of the most useful skills are:
critique
An adversarial review mode. It moves the agent out of “does this seem plausible?” and into “what would break this?” It forces the agent to enumerate failure modes, verify claims against the actual source, and challenge its own assumptions before a pull request or design document goes out.
refine
A way to turn a rough idea into an implementation-ready spec before writing code. It defines scope, acceptance criteria, risks, and estimated effort. Catching a weak idea at the spec stage is much cheaper than finding it halfway through implementation.
pr-merge
A merge protocol. Required checks, review state, smoke testing, squash merge, branch cleanup, issue closure. Merging is one of the riskiest moments in the workflow, so it is one of the least improvised.
reflect
The mechanism that turns friction into system improvement.
This is where the workflow becomes more than a set of documents.
Turning retrospectives into guardrails
Most teams have some version of the same problem.
Something goes wrong. A retrospective captures the lesson. Everyone agrees to “always do X next time.” Then time passes, attention moves, and the lesson becomes a sentence in a document nobody checks at the moment it matters.
We are trying to make that failure mode harder.
When a mistake costs us a cycle, we do not only write down the lesson. We try to encode it into the system.
Sometimes that means updating a skill. Sometimes it means adding a memory entry. And sometimes it means creating a hook: a small program that runs automatically and blocks the wrong move before it happens.
These hooks are not theoretical best practices. They are scars turned into reflexes.
A few examples:
Ask before building.
If an agent is about to write code without clarifying scope in the current session, it is stopped and made to ask first. Ambiguous prompts create churn. The hook makes clarification the default rather than a matter of discipline.
No second blind fix.
An agent cannot edit the same source file a second time unless the earlier attempt added instrumentation or brought in the debugger. This enforces the “hypothesis first” rule in code.
Consult the map before going too deep.
If an agent is several edits into core services without consulting the feature map, it is blocked until it does. This protects against local search masquerading as system understanding.
Do not loop.
Repeated edits to the same file, or expanding the touched surface without a visible plan, triggers a step back into planning or critique.
Review before pushing.
A branch cannot be pushed or turned into a pull request until an independent review pass has run.
No empty smoke handoffs.
An agent cannot tell me something is ready to test unless it has actually built and tested first.
The pattern matters more than any individual hook.
A mistake happens once. The system absorbs the lesson. The next time, the better behavior is easier than repeating the old one.
That is the difference between documentation and operational memory.
The loop that makes the system improve
The strongest part of the workflow is the closed loop.
Friction happens.
reflect captures it.
The lesson becomes a memory entry, a skill update, or a hook.
The next time the same situation appears, the system enforces the improved behavior automatically.
There is also a discipline around pruning.
The persistent memory layer is not allowed to grow forever. It gets cut back when entries no longer change decisions or when the lesson has already moved into code, skills, or the constitution.
That matters because every process has a failure mode. A system that only accumulates rules eventually becomes too heavy to use. The goal is not more process. The goal is better judgment embedded in the workflow.
The result is a development practice that gets better at its own job over time without relying on one person to remember every previous mistake.
Two AI agents checking each other’s work
The review loop is where much of the quality comes from.
When Claude opens a pull request, Codex reviews it on its next cycle. When Codex implements a change, Claude can review it. The reviewer can approve, request changes, or block the work, and the verdict flows back through GitHub labels and comments.
The useful part is not that another model looked at the code.
The useful part is that the review is structured, adversarial, and grounded in the current source.
In one session, a single feature spec went through five rounds of Codex review. Each round caught something real: a method signature that did not exist, a UI assumption that would not compile, and a reactive-state issue that could have shipped quietly.
That kind of review is valuable because it catches a specific class of failure: the change that looks coherent in isolation but breaks when it touches the actual product.
Tests matter. Human product judgment matters. But an independent AI reviewer, forced to inspect the current source and challenge the implementation, adds a useful layer of pressure before the work reaches me.
What this changes for a small studio
The common way to talk about AI in software is still too model-centric.
Which model is best? Which one codes fastest? Which one has the largest context window?
Those questions matter, but they are not the main thing.
A powerful model with no role, no shared state, no accountability, and no memory of previous mistakes is unreliable on a real codebase. It may be impressive in moments, but the workflow around it will still be fragile.
A very good model inside a disciplined system is different.
It has a role. It has a source of truth. It has a reviewer. It has procedures. It has guardrails created from actual failure. It has a feedback loop that improves the way it works.
That is the part we have been building at Zalo Design Studio.
Not just prompts. Not just better autocomplete. Not a smarter chatbot next to the work.
An operating system around AI agents: a constitution they both obey, GitHub as the coordination bus, a knowledge map to prevent shallow changes, skills that make repeated work reliable, hooks that turn mistakes into guardrails, and a reflection loop that keeps the system improving.
The models will keep getting better. Everyone will have access to that improvement.
The leverage comes from what you build around them.
For us, that means a small, accountable, self-improving team, mostly artificial, building real software under a human product owner who still makes the calls.
That is what advanced AI use looks like here.
Not replacing judgment.
Building a system that lets judgment travel further.
Built and operated at Zalo Design Studio. The product these agents work on, MetaScope, is a professional metadata editor for macOS. The operating system around the agents is the part we think is worth studying.